MySQL 实用技巧
zerofill 零填充
面试官:int(1) 和 int(10) 有什么区别? (qq.com)
即:一般 int 后面的数字,配合 zerofill 一起使用才有效。
CREATE TABLE `user` (
`id` int(4) unsigned zerofill NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;查询时会自动填充 0,但底层存储不变:
mysql> select * from user;
+------+
| id |
+------+
| 0001 |
| 0010 |
| 0100 |
| 1000 |
+------+
4 rows in set (0.00 sec)性能优化
总结MySQL 8种性能优化方式_9、mysql如何进行性能优化_墨 云的博客-CSDN博客
1、索引
创建索引
建表时创建索引:
create table t(id int,name varchar(20),index idx_name (name));
给表追加索引:
alter table t add unique index idx_id(id);
给表的多列上追加索引
alter table t add index idx_id_name(id,name);
或者:
create index idx_id_name on t(id,name);
查看索引
使用show语句查看t表上的索引:
show index from t;
或者:
show keys from t;–mysql中索引也被称作keys
使用show create table语句查看索引:
show create table t;
删除索引:
使用alter table命令删除索引:
alter table 表 drop index 索引名
使用drop index命令删除索引:
drop index 索引名 on 表2、使用 EXPLAIN 来查看你的 SELECT 查询
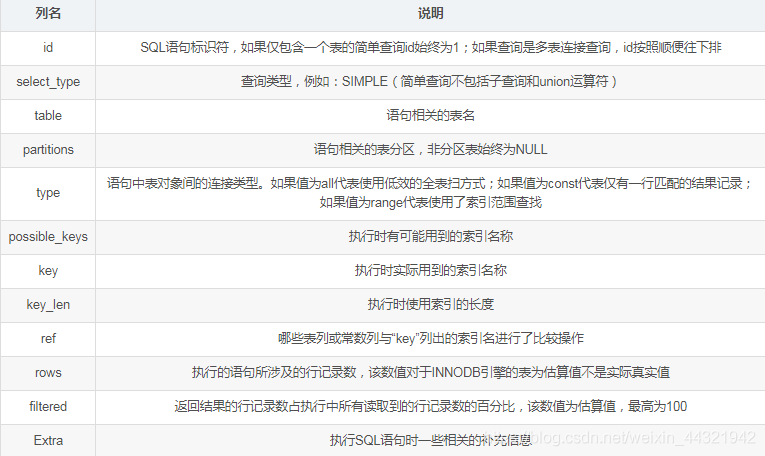
关于 MySQL 服务器是如何执行 SQL 语句的相关信息可以用 explain 语句来查看,可以用 explain 语句查看执行过程的语句主要有 select、insert、update、delete 等,其使用方式是 explain 后接具体的增删改查 SQL 语句,如:explain select * from test.t;
其中每个字段代表的含义如下:
通过:type、possible_keys和key三个字段,我们能清楚的知道查询语句是否使用了索引和使用了哪个索引。
3、不要使用表达式作为查询条件
方式一(错误,不走索引): select * from t where id+1<5;
方式二(正确): select * from t where id<4;
4、尽量使用 in 运行符来替代 or 运算
方式一:select * from t where id=1 or id=2 or id=3;
方式二:select * from t where id in (1,2,3);
5、条件列表值如果连续使用 between 替代 in
继续以上实验,从t表中仅要找出id值为1,2,3的行,因为id值连续,可以使用以下第三种方式书写SQL语句:
方式三:select * from t where id between 1and 3;
速度:方式三 > 方式二 > 方式一
6、无重复记录的结果集使用 union all 合并
MySQL数据库中使用union或union all运算符将一个或多个列数相同的查询结果集上下合并成为一个查询结果集。其中union会合并各个结果集中相同的记录行,重复记录只显示一次外加自动排序,而union all运算符不去重不排序。因此,对于无重复记录的多个查询结果集应当使用union all合并。
方法一:select * from t where id=1 union select * from t where id=2;
方法二:select * from t where id=1 union all select * from t where id=2;
7、有条件使用where就不使用having
在SELECT查询语句中,where子句和having子句都起到对行记录过滤的作用,主要区别在于having子句是对group by子句产生的结果(可能包含聚合函数),而where子句先于having子句运行,主要目的是缩减查询结果集的行记录数。实验需要复杂一些的数据表,可以通过http://downloads.mysql.com/docs/world.sql.zip链接下载MySQL例子数据库。该数据库包含,country(国家),city(城市)和countrylanguage(国家语言)三张数据表。例子数据库下载解压后包含world.sql文件,使用mysql客户端的source命令运行后,会创建包含前述三张表的world数据库。
方式一:select CountryCode,count() from city where CountryCode=‘CHN’;
方式二:select CountryCode,count() from city group by CountryCode having CountryCode=‘CHN’;
8、使用 like 操作符时通配符要放在右侧
在书写 SQL 语句时,如果在 where 或 having 子句中使用 like 模糊匹配操作符,通配符 “%” 或 “_” 不要写在匹配字符串的左侧,参见以下两种书写方式:
方式一:select * from t where name like ‘150’;
方式二:select * from t where name like ‘%150_’;
使用 like 操作符的查询条件列带有索引时,如果通配符放在最左边,索引会失效,SQL 优化器会选择效率低的全表扫解析方式,主要原因是对字符串类型创建索引时,MySQL 将从最左开始选取一部分(767 字符,最多到 3072 字符)字符串,将其内容存入到索引中。如果查询条件最左侧是可以匹配任意字符的通配符,无法定位具体的索引键值,优化器就会选择其他获取数据的方式而忽略索引的存在。因此,当带有索引的查询条件列是字符类型,如果使用模糊匹配操作符,不要将其放在最左侧,要放到第一个具体字符的右侧。
9、补充:数据库怎么优化查询效率?
- 储存引擎选择:如果数据表需要事务处理,应该考虑使用 InnoDB,因为它完全符合 ACID 特性。如果不需要事务处理,使用默认存储引擎 MyISAM 是比较明智的。
- 对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描。
- Update 语句,如果只更改 1、2 个字段,不要 Update 全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
- 对于多张大数据量(这里几百条就算大了)的表 JOIN,要先分页再 JOIN,否则逻辑读会很高,性能很差。

 豫公网安备 41010702003051号
豫公网安备 41010702003051号


全部评论