MongoDB 的读写过程
参考
MongoDB 的查询过程
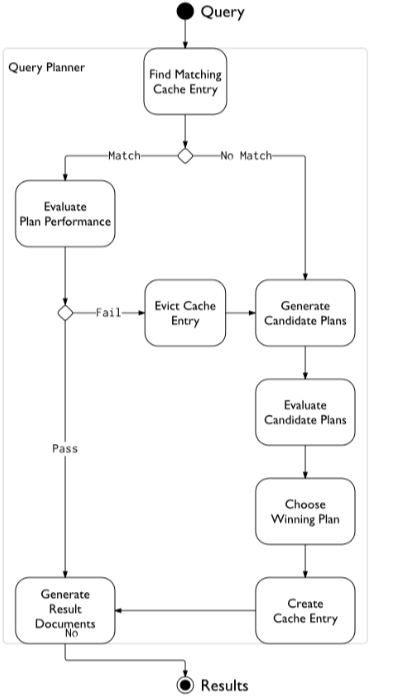
mongodb 的查询过程是一个比较复杂的过程, 从查询语句到查询计划的执行, 中间经历了如下的几个步骤:
- 生成语法树 (matchExpression);
- 逻辑优化过程:由MatchExpression 生成 CanoncalQuery;
- 生成查询计划: 由CanoncalQuery生成QuerySolution和 MultiPlanStage;
- 生成PlanExecutor;
- 执行计划。
1、生成语法树
从一个 Bson 类型的 filter, 生成一个 MatcgExpression 树, 具体的实现可以参考: http://blog.csdn.net/baijiwei/article/details/78127191;
2、逻辑优化过程
通过 MatchExpression, 我们可以得到 filter 的所有的设定, 但是,这个设定可能是散乱的, 效率不高的, 逻辑优化过程的主要作用就是优化 filter 的设定, 使得在语义保持不变的前提下, 能够更加有效的执行。
该过程主要通过 CanonicalQuery 类来实现,其实现细节可以参考: http://blog.csdn.net/baijiwei/article/details/78170387 。
该过程主要包含三个方面:
- Normoralize tree;
- sort tree;
- validate tree;
3、生成查询计划
通过 CanonicalQuery 和 MatchExpression, 类 PlanEnumerator 罗列 MatchExpression 的各种可能的组合(indexScan & collectionScan等), 生成具体的 MatchExpression, 产生出来一个个的 QueryPlan。 具体的实现在函数:QueryPlannerAccess::buildIndexedDataAccess, 生成一个树形的QuerySolutionNode 树。
如果 QuerySolution 的个数大于 1, 生成一个 MultiPlanStage 对象, 每个 QuerySolution 对应于一个 PlanStage 或者其子对象,planStage 对象由函数StageBuilder::build 生成。其实现细节可以参考: http://blog.csdn.net/baijiwei/article/details/78174198。
4、生成 PlanExecutor
PlanExecutor::PlanExecutor(OperationContext* opCtx,
unique_ptr<WorkingSet> ws,
unique_ptr<PlanStage> rt,
unique_ptr<QuerySolution> qs,
unique_ptr<CanonicalQuery> cq,
const Collection* collection,
const string& ns)如上述的代码片, 前面我们得到了 PlanStage, QuerySolution 以及 CanonicalQuery, 可以生成一个指定的 PlanExecutor,查询计划的最终的执行是由该类的对象处理的。生成最优的执行计划, MultiPlanStage::pickBestPlan 最终选择由该函数实现, 具体的打分过程在 PlanRanker::pickBestPlan。
5、执行查询计划
最终的执行过程非常简单:遍历 PlanExecutor::getNextImpl:
while (PlanExecutor::ADVANCED == (state = exec->getNext(&obj, NULL))) {
WorkingSetID id = WorkingSet::INVALID_ID;
PlanStage::StageState code = _root->work(&id);
WorkingSetMember* member = _workingSet->get(id);
bool hasRequestedData = true;
...
if (hasRequestedData) {
_workingSet->free(id);
return PlanExecutor::ADVANCED;
}
}这里_root 是 PlanStage*, 所有的 planStage 的 ID 保存在一个list里面:std::list results;函数 PlanStage::work 就是从前往后, 得到一个个的 WorkingSetID。相关的实现细节参考: http://blog.csdn.net/baijiwei/article/details/78195766。
MongoDB 的写入过程
MongoDB 在写入前,首先需要与服务器进行连接再发送请求,服务端的处理流程如下:
- Mongod 在启动时会创建一个 PortMessageServe r对象,其调用 setupSockets 为 mongod 配置的每个地址创建一个 socket,并 bind 地址,然后调用initAndListen 监听所有的地址,调用 select 等待监听 fd 上发生的链接时间,调用 accept 系统接受新的连接请求,并为每个连接创建一个线程,执行handleIncomingMsg 方法。
- handleIncomingMsg 会创建一个新的 Client 对象,并不断调用 recv 从连接上读取请求,并将请求反序列化为 Message 对象,并调用MyMessageHandler::process 方法处理请求。
- MyMessageHandler::process 会调用 assembleResponse 方法,从 Message 对象里获取请求类型,根据请求类型进行相应的处理。如果是 dbInsert,会调用 receivedInsert 处理,再调用 database 类的接口定位对应的 Collection 对象,然后调用 insertDocement 往集合写入文档。
接下来解释一下MongoDB的存储引擎:
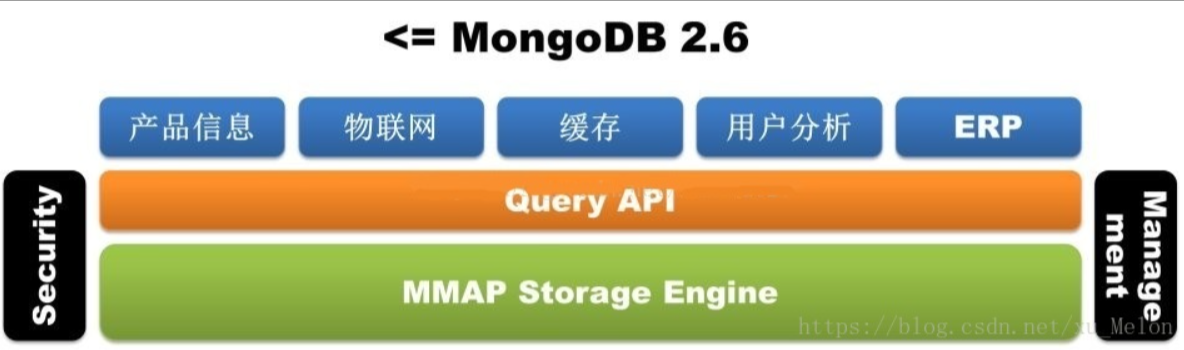
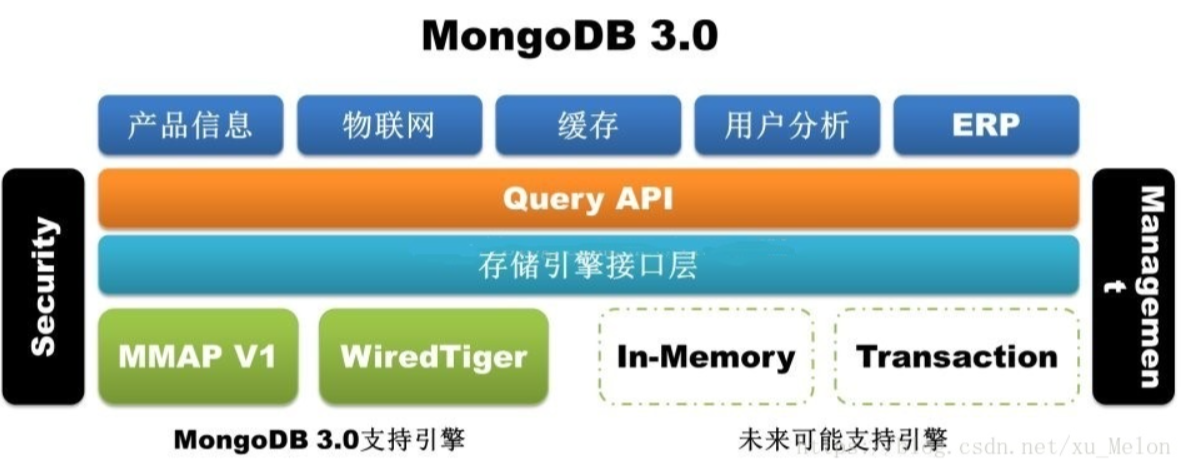
从 MongoDB 3.0 之后引入的 WiredTiger 弥补了 MMAP 存储引擎自身的天然缺陷(耗费磁盘空间和内存空间且难以清理,更致命的是库级别锁)。
WiredTiger 通过 MVCC 实现文档级别的锁,这样就允许了多个客户端请求同时更新一个集合内的不同文档。
回归主题,上文说到调用 insertDocement 来写文档,那么存储引擎的处理过程就是,先写 journal 日志,然后通过多版本并发控制(MVCC)。操作开始之时,WiredTiger 提供了一个时间点快照。快照提供了内存数据的一致性视图,这样就能修改该文档内容。
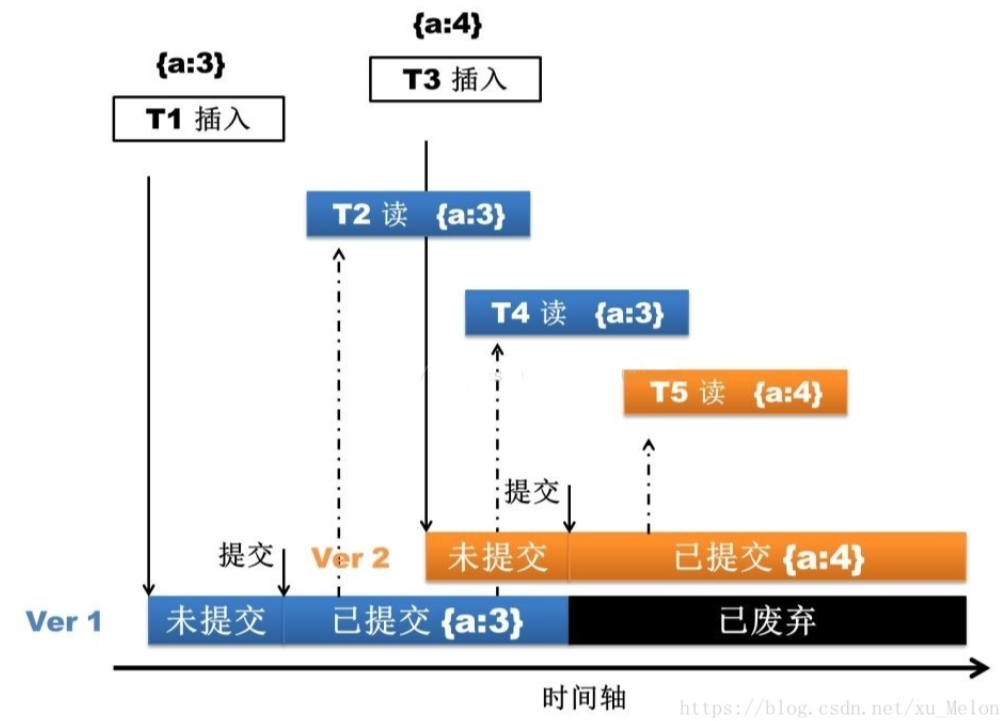
都知道 NoSQL 快,其实上文并没有体现,关键快在,MongoDB 修改的是内存的文档,接着就直接返回了。接下来就有必要了解一下这过程的详细信息。
Mongo 使用了内存映射技术——写入数据时候只要在内存里完成就可以返回给应用程序,而保存到硬体的操作则在后台异步完成。先了解一下Memeory-Mapped Files:
- 内存映射文件是 OS 通过 mmap 在内存中创建一个数据文件,这样就把文件映射到一个虚拟内存的区域。
- 虚拟内存对于进程来说,是一个物理内存的抽象,寻址空间大小为 2^64
- 操作系统通过 mmap 来把进程所需的所有数据映射到这个地址空间(红线),然后再把当前需要处理的数据映射到物理内存(灰线)
- 当进程访问某个数据时,如果数据不在虚拟内存里,触发 page fault,然后 OS 从硬盘里把数据加载进虚拟内存和物理内存
- 如果物理内存满了,触发 swap-out 操作,这时有些数据就需要写回磁盘,如果是纯粹的内存数据,写回 swap 分区,如果不是就写回磁盘。
MongoDB 把文档写进内存之后就返回了,那么接下来的数据的一致性问题、持久化问题,就由上文点到的 journal 日志来实现了。默认情况下 mongodb 每 100 毫秒往 journal 文件中 flush 一次数据,默认每隔 60 秒,MongoDB 请求操作系统将 Shared view 刷新输出到磁盘,此外,journal 日志还可以用来做备份容灾。
这样 Mongo 的一次数据写入过程才算完成。

 豫公网安备 41010702003051号
豫公网安备 41010702003051号


全部评论